












































In an era where artificial intelligence (AI) and machine learning (ML) are driving unprecedented innovation and efficiency, a new class of cyber threats has emerged that puts sensitive data and entire business operations at serious risk. Among these threats, model inversion attacks have become particularly concerning for organizations that rely on machine learning models trained on proprietary or personal data. Unlike traditional data breaches that target databases or network vulnerabilities, model inversion attacks exploit the learning patterns of machine learning models themselves to extract confidential information without ever accessing the underlying dataset directly.
This blog explores what the attacks are, how they work, why they are increasingly a business concern, and what organizations can do to protect themselves.
Table of Contents
What Are Model Inversion Attacks?
A model inversion attack is a form of privacy attack against machine learning systems in which an adversary uses the outputs of a model to infer sensitive information about the data used to train it. Rather than breaching a database or stealing credentials, attackers observe how a model responds to input queries and leverage those outputs, often including confidence scores or probability values, to reconstruct aspects of the training data that should remain private.
Machine learning models do not just generalize patterns from training data; they also inherently “remember” details about that data, especially when the dataset is small or models are over-parameterized. By crafting specific inputs and analyzing the corresponding outputs repeatedly, attackers can reverse-engineer sensitive features, such as personal attributes or proprietary information, embedded within the model.
This type of attack differs fundamentally from other ML attacks, such as membership inference, which aims to determine whether a specific data point was part of the training set, and model extraction, which seeks to copy the model itself. Model inversion instead focuses on reconstructing sensitive training data from a deployed model’s behavior.
Impact of Model Inversion Attacks on Organizations
Successful model inversion attacks can inflict significant damage across multiple areas of a business. When attackers extract sensitive training data from machine learning models, organizations face not only immediate financial losses but also lasting reputational harm and operational setbacks that continue well beyond the initial incident.
The financial impact typically starts with incident response and forensic investigations, but escalates rapidly. According to the 2025 Cost of a Data Breach Report, the global average cost of a breach has risen to $4.88 million, with healthcare organizations experiencing even higher averages of $9.77 million per incident. If model inversion exposes protected health information or financial data, organizations must comply with mandatory breach notification laws, which can increase costs through regulatory fines, legal liabilities, and potential class-action lawsuits.
Reputational consequences are more difficult to measure but can be even more damaging. When customers and partners discover that their sensitive information was reconstructed from machine learning model outputs, trust erodes quickly. This loss of confidence can impact customer retention, partnership opportunities, and overall market positioning, particularly in industries where strong data protection practices are a competitive advantage.
Operational challenges also arise as organizations are forced to respond urgently by:
- Retraining or decommissioning compromised models
- Applying emergency access controls to machine learning endpoints
- Conducting privacy impact assessments across deployed models
- Notifying affected individuals and regulators within mandated timelines
These effects often influence broader AI strategies, prompting organizations to reassess how model inversion risks align with their overall cybersecurity and risk management frameworks.
How Model Inversion Attacks Work?
The technical execution typically follows a structured exploitation sequence. Attackers target inference-time privacy by moving through multiple stages, submitting carefully crafted queries, studying the model’s responses, and gradually reconstructing sensitive attributes from the outputs. Because these activities can resemble normal usage patterns, such attacks frequently remain undetected when monitoring systems are not specifically tuned to identify machine learning–related security threats.
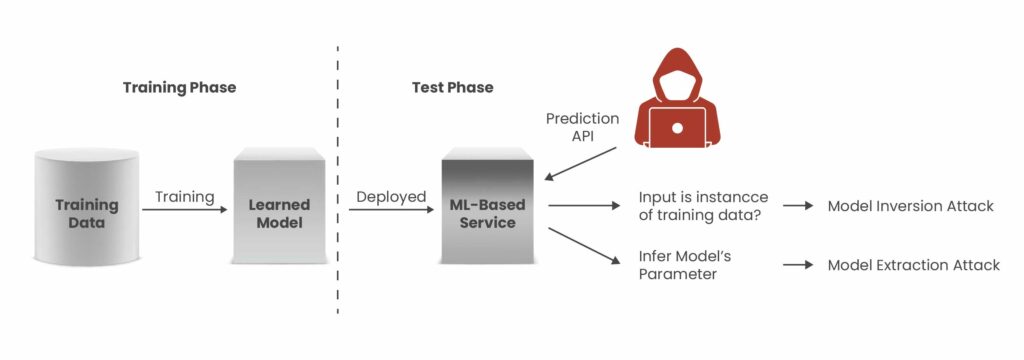
- Access the Model’s API or Prediction Interface:
Attackers need a way to submit inputs and receive outputs. This could be an exposed REST API for a chatbot, image classifier, or any ML-powered service. - Submit Well-Crafted Queries:
The attacker sends a large number of carefully designed input queries. These queries are selected or generated such that the resulting outputs reveal subtle correlations that can be exploited. - Analyze Predictions and Confidence Scores:
Many models return not just a predicted output class (e.g., “approved” or “denied”) but also confidence values or probability distributions. These outputs contain more information than is immediately apparent, and attackers can leverage them to infer training data attributes. - Iterative Reconstruction:
Through iterative refinement processes, adjusting inputs based on previous outputs, attackers can reconstruct data features or even full entries from the original training dataset.
Model inversion attacks work in both black-box scenarios (where attackers only see outputs for provided inputs) and white-box scenarios (where attackers have full access to model parameters), making them a versatile and powerful threat.
Get in!
Join our weekly newsletter and stay updated
Examples of Attack Scenarios
Below are practical cases that demonstrate the risks posed by model inversion attacks.
Scenario 1: Extracting Personal Data from a Face Recognition Model
In this scenario, an attacker develops a deep learning model designed for facial recognition and then leverages it to conduct a model inversion attack against another organization’s face recognition system. By submitting images to the target model and analyzing its prediction outputs, the attacker attempts to reconstruct sensitive personal information associated with those individuals, such as names, addresses, or even social security numbers.
The attack is carried out by using the attacker’s own trained model to reverse-engineer or approximate the outputs of the target system. This may involve exploiting weaknesses in the model’s implementation or interacting with it through exposed APIs. By systematically analyzing the prediction responses, the attacker can infer and recover sensitive data embedded within or learned by the original model.
Scenario 2: Circumventing a Bot Detection Model in Online Advertising
In this case, an advertiser seeks to automate campaign performance by deploying bots to click ads and browse websites. However, advertising platforms rely on bot detection models to distinguish between legitimate human traffic and automated activity. To evade these safeguards, the advertiser develops a deep learning model trained to replicate bot detection behavior and uses it to perform a model inversion attack against the platform’s detection system.
By analyzing how the target model classifies inputs, the advertiser refines their bots’ behavior to mimic legitimate user patterns. Through repeated interaction, potentially via exposed APIs or by exploiting implementation weaknesses, they reverse-engineer the detection logic and adjust their automation accordingly.
As a result, the bots are modified to appear as genuine human users, enabling the advertiser to bypass detection controls and execute automated advertising campaigns without being flagged by the platform.
Book Your Free Cybersecurity Consultation Today!

How Can Model Inversion Attacks Be Prevented?
1) Restrict and Authenticate Model Access
Ensure that only authorized users and applications can access machine learning models. Implement strong authentication mechanisms (such as API keys, OAuth, or multi-factor authentication) and role-based access control (RBAC). Limiting public exposure of ML APIs significantly reduces the attack surface available for model inversion attacks.
2) Limit Output Information
Avoid returning excessive prediction details such as confidence scores, probability distributions, or intermediate feature outputs. The more detailed the output, the easier it becomes for attackers to reverse-engineer sensitive training data. Providing only the final decision or classification result reduces information leakage.
3) Implement Rate Limiting and Query Monitoring
Model inversion attacks typically require large volumes of carefully crafted queries. Applying rate limiting on APIs and monitoring abnormal query behavior can help detect and block suspicious activity before attackers can gather enough data for reconstruction.
4) Apply Differential Privacy
Differential privacy introduces controlled noise into the training process or model outputs, making it statistically difficult to extract individual data points from the model. This ensures that even if an attacker queries the model extensively, reconstructing specific training data remains infeasible.
5) Continuous Monitoring and Logging
Maintain detailed logs of model interactions and implement anomaly detection systems. Continuous monitoring enables early detection of suspicious iterative querying patterns commonly used in model inversion attacks.
Ways Kratikal Helps Businesses Mitigate Model Inversion Risks?
Kratikal strengthens AI security by offering specialized AI penetration testing that emulates real‑world adversarial attacks against machine learning models and AI systems to uncover vulnerabilities before threat actors can exploit them. Our methodology is aligned with OWASP’s LLM Top 10 risk framework. It uncovers risks such as sensitive data leakage, prompt injections, and insecure integrations. We then provide remediation guidance tailored to how your AI is deployed, whether as APIs, chatbots, or other AI workflows. Kratikal’s approach not only prevents unauthorized access and protects sensitive data but also enhances compliance with emerging AI security standards and builds trust with customers and regulators by ensuring the reliability and integrity of AI outputs.
Final Thoughts
As AI adoption grows, model inversion attacks present a serious business risk that extends beyond technical vulnerabilities. These attacks can expose sensitive data, trigger regulatory penalties, damage reputation, and disrupt operations. Since they target the intelligence layer of machine learning systems, they are often harder to detect than traditional cyber threats.
At this critical intersection of AI innovation and security, Kratikal helps organizations proactively secure their machine learning ecosystems. From AI security assessments and red teaming to privacy risk analysis and secure deployment architecture reviews, Kratikal enables businesses to identify vulnerabilities before adversaries exploit them.
FAQs
- Why are model inversion attacks risky?
Model inversion attacks bypass traditional data protection by extracting sensitive information directly from deployed AI models, without accessing databases. Attackers can reconstruct health records, financial data, biometric details, or proprietary business information simply by analyzing model outputs.
- Can differential privacy fully eliminate the risk of model inversion attacks?
Differential privacy can greatly minimize the risk of model inversion attacks, but it must be carefully balanced to maintain model performance. For stronger protection, it should be combined with layered security measures such as strict access controls, limited output exposure, and continuous behavioral monitoring.
- What is the model inversion problem?
The model inversion problem involves determining the input signal that corresponds to a specific output (reference) signal. This task is expressed as a nonlinear dynamic optimization problem in the time domain and is efficiently solved.





Leave a comment
Your email address will not be published. Required fields are marked *