












































Organizations collect and store huge amounts of sensitive data, customer details, financial records, login credentials, and more. Protecting this data is not just important; it’s critical for business survival. One of the most commonly used techniques to protect sensitive data is data masking.
At first glance, it seems like a strong solution. It hides sensitive information so that it cannot be easily accessed or misused. However, many organizations make a mistake; they assume that implementing data masking automatically makes their data secure.
The truth is very different.
If not implemented properly, this can leave serious gaps in your security. These gaps can expose your organization to data breaches, compliance failures, and insider threats. In this blog, we will explore the key gaps and how they can put your organization at risk.
Table of Contents
What is Data Masking?
Before diving into the gaps, let’s quickly understand what data masking means.
It is the process of replacing sensitive data with fake or scrambled values. The goal is to make the data usable for testing or analysis without revealing the real information.
There are different types of data masking:
- Static Data Masking (SDM): Masks data in a copy of the database
- Dynamic Data Masking (DDM): Masks data in real-time when accessed
- Tokenization: Replaces data with tokens
- Encryption-based masking: Secures data using encryption
While these methods are useful, their effectiveness depends on how they are applied.
Common Data Masking Gaps
Even well-implemented strategies can have hidden gaps that expose sensitive information. Here are some of the most common ones organizations often overlook:
- Masking Only in Production
One of the biggest mistakes organizations make is applying data masking only in production environments.
In reality, data is often copied from production to:
- Testing environments
- Development environments
- Analytics platforms
These environments usually have weaker security controls.
The problem:
Sensitive data remains unmasked in non-production environments, making them easy targets for attackers.
- Weak Masking Techniques
Not all methods are strong enough to protect data.
Simple masking methods like:
- Replacing characters with “X.”
- Partial masking can be easily reversed or guessed.
Example:
If only the last four digits of a credit card are visible, attackers can still use patterns or other data sources to guess the full number.
The problem:
Weak masking does not fully protect sensitive data.
- Lack of Data Context
It is often applied without understanding the full context of the data.
For example:
- Name is masked
- But address, phone number, and transaction history are visible
The problem:
Even if one field is masked, other related data can reveal the identity of a person. This is known as a re-identification risk.
- Logs and Debug Files Are Ignored
Applications often store sensitive data in:
- Logs
- Debug files
- Monitoring tools
Developers sometimes forget to mask data in these areas.
The problem:
Even if your database is secure, attackers can extract sensitive data from logs.
- One-Time Masking Without Updates
Many organizations apply data masking only once and forget about it.
However:
- New data is added daily
- Databases change
- New fields are introduced
The problem:
New or updated data may remain unmasked, creating hidden risks.
Book Your Free Cybersecurity Consultation Today!

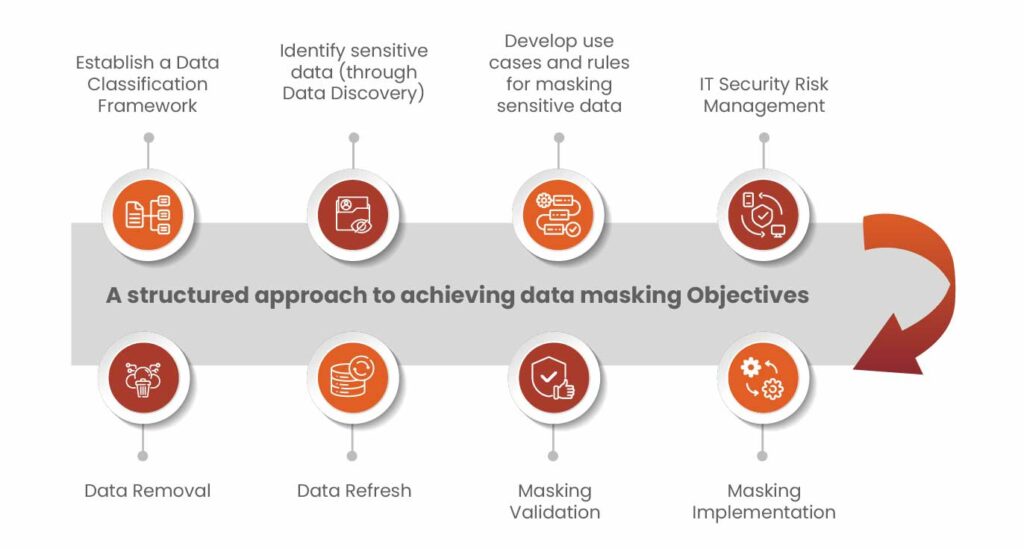
How to Fix These Data Masking Gaps?
To make this effective, organizations need a more complete approach.
- Mask Data Everywhere
Apply it across:
- Production
- Testing
- Development
- Analytics systems
Consistency is key.
- Use Strong Masking Techniques
Avoid basic masking methods. Instead, use:
- Tokenization
- Encryption
- Format-preserving masking
These methods provide better protection.
- Understand Data Relationships
Mask data based on context, not just individual fields.
For example: If you mask names, also review related fields like address and phone number
This reduces re-identification risks.
- Limit Access to Sensitive Data
Follow the principle of least privilege:
- Only give access to those who need it
- Monitor user activity
- Restrict access to unmasked data
Implementation Checklist and Key Pointers
| Action Items | Key Pointers |
| Identify Sensitive Data Sources | • Discover all data locations (DBs, cloud, files)• Include PII, PHI, PCI data |
| Classify Tag Data | • Use automated tools for tagging• Update tags with schema changes |
| Implement Data Masking | • Apply masking in non-prod and APIs• Use strong methods (tokenization, FPE) |
| Secure Logs | • Mask or remove sensitive data in logs• Restrict access using RBAC |
| Encrypt Data in Transit | • Use TLS/SSH for all communications• Encrypt backups and data flows |
| Add Privacy for Analytics | • Use privacy-preserving techniques• Limit exposure in data analysis |
| Security Testing & Audting | • Perform regular security testing• Conduct compliance audits regularly |
Get in!
Join our weekly newsletter and stay updated
Conclusion
Data masking is a strong security method, but it only works well if done properly. If masking rules are not consistent or some areas are left uncovered, sensitive data can still be exposed. Many risks come from places like old databases, logs, or analytics systems where data may not be masked.
To stay secure, organizations should apply this across all environments, treat masking rules as part of their regular development process, and combine it with other controls like encryption and privacy techniques. Since regulations like GDPR, HIPAA, and PCI require strict data protection, it’s important to align your masking strategy with these standards and keep it updated.
FAQs
- Why is data masking important for organizations?
It protects sensitive data from breaches, insider threats, and misuse, especially in non-production environments.
- How to implement data masking in an organization?
Identify sensitive data, define policies, and apply masking across all systems and environments.
- How to prevent re-identification in masked data?
Mask-related fields and use advanced techniques like tokenization or differential privacy.
- What are common data masking gaps and risks?
Unmasked logs, weak masking techniques, and inconsistent policies across environments
- How to prevent re-identification in masked data?
Mask related fields and use advanced techniques like tokenization or differential privacy.




Leave a comment
Your email address will not be published. Required fields are marked *