












































The rapid adoption of artificial intelligence (AI) agents across industries has brought significant benefits but also increased exposure to cyber threats, particularly adversarial attacks. According to the Deloitte Threat Report, nearly 30% of all AI cyberattacks now involve adversarial techniques such as training data poisoning, model theft, and adversarial sample manipulation, which can cause AI models to produce incorrect, biased, or even harmful outcomes. As AI models become critical to decision-making in sectors like finance, healthcare, and manufacturing, strengthening their security is no longer optional. Organizations must implement robust defense mechanisms, continuous monitoring, and adversarial attack detection to secure these models against exploitation and ensure that AI agents remain reliable, accurate, and secure.
Table of Contents
- 0.1 Adversarial Attacks on AI Models
- 0.1.1 Common Types of Adversarial Attacks
- 0.1.2 Strategies to Protect AI Agents Against Adversarial Threats
- 0.1.2.1 Implementation of Adversarial Training
- 0.1.2.2 Input Validation and Sanitization
- 0.1.2.3 Apply Model Hardening Techniques
- 0.1.2.4 Implement Ongoing Monitoring and Threat Detection
- 0.1.2.5 Restrict Access With Strong Authentication & Authorization Controls
- 0.1.2.6 Implement Differential Privacy for Data Security
- 0.1.2.7 Conduct Regular AI Security Audits & Penetration Testing
- 0.1.2.8 Use Explainable AI (XAI) to Improve Transparency
- 1 Get in!
Adversarial Attacks on AI Models
An adversarial attack is an attempt to deceive a machine learning model by providing malicious input that causes it to make incorrect predictions or classifications. Unlike traditional cyberattacks that exploit software flaws, adversarial attacks target the model’s training data, decision boundaries, or inference logic.
In financial services, where AI models decide loan approvals, detect fraud, or flag suspicious transactions, even small manipulations can lead to catastrophic consequences.
Common Types of Adversarial Attacks
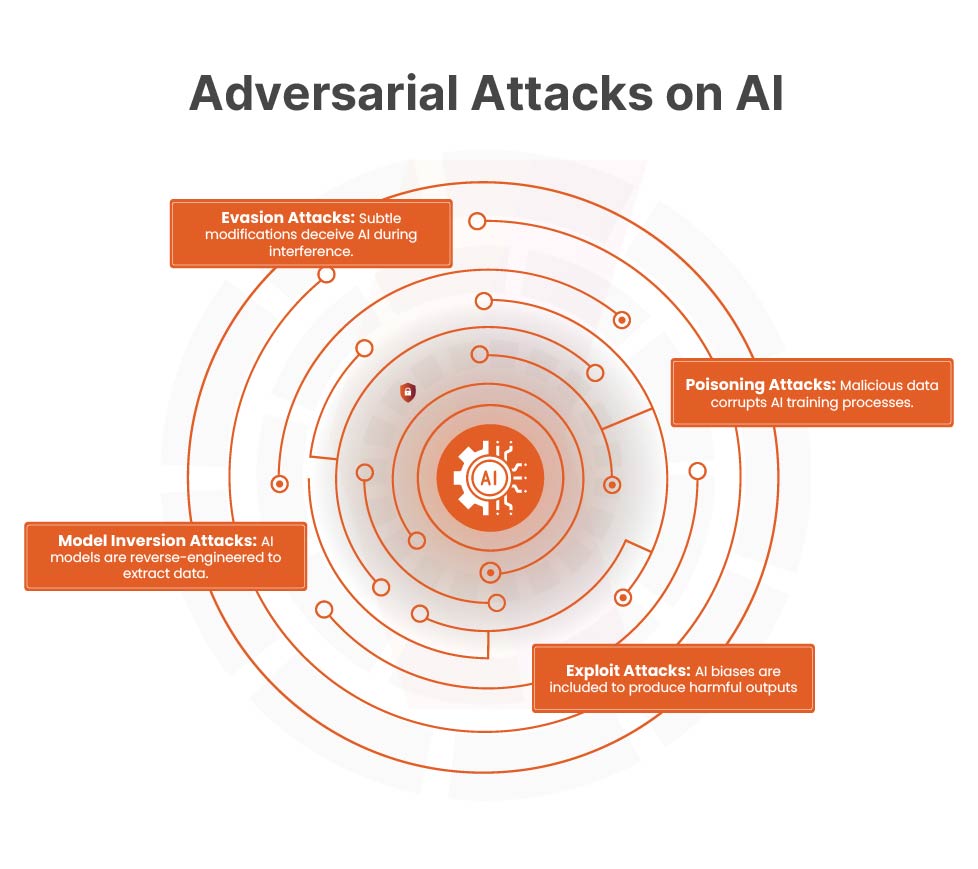
Evasion Attacks (Inference-Time Attacks):
Evasion attacks occur when attackers subtly manipulate input data to trick an AI model into making incorrect decisions during inference (real-time predictions). These alterations are often so small that they are invisible to humans, yet they can significantly distort the model’s output.
How It Works:
Attackers introduce minor changes to images, text, or numerical data to mislead AI systems. For instance:
- A fraud detection model might be deceived by slightly altered transaction data, allowing fraudulent activity to go undetected.
- A self-driving car’s AI could mistake a stop sign for a speed limit sign if the sign’s appearance is subtly modified.
- A facial recognition system can be manipulated to misidentify individuals through adversarial patches or minimal distortions.
Model Inversion Attacks
Model inversion attacks enable adversaries to reverse-engineer AI models and extract sensitive information from them. By exploiting the model’s responses, attackers can reconstruct portions of the training data — potentially revealing confidential customer information.
How It Works:
- Attackers repeatedly query the AI model with carefully crafted inputs.
- They analyze the model’s outputs to infer patterns and relationships within the training data.
- This process can reveal sensitive details such as personal records, policyholder information, or other confidential data.
Poisoning Attacks
A poisoning attack occurs when adversaries inject malicious or manipulated data into an AI model’s training set. This compromises the model’s learning process, leading it to produce incorrect outcomes even for valid inputs.
How It Works:
Attackers achieve this by:
- Inserting deceptive records into training datasets.
- Altering customer data so the AI forms false correlations.
- Introducing biased data to deliberately skew decision-making.
Book Your Free Cybersecurity Consultation Today!

Exploit Attacks
Exploit attacks target vulnerabilities in AI models to trigger biased, incorrect, or harmful outputs. These attacks leverage existing biases in training data or introduce new ones, altering the model’s behavior in a way that benefits the attacker.
How It Works:
- Attackers send repeated queries to identify weaknesses in the model’s decision-making process.
- They exploit these weaknesses to manipulate the model into producing biased or advantageous outputs.
- In some cases, attackers modify AI-generated content to spread misinformation or disinformation.
Strategies to Protect AI Agents Against Adversarial Threats
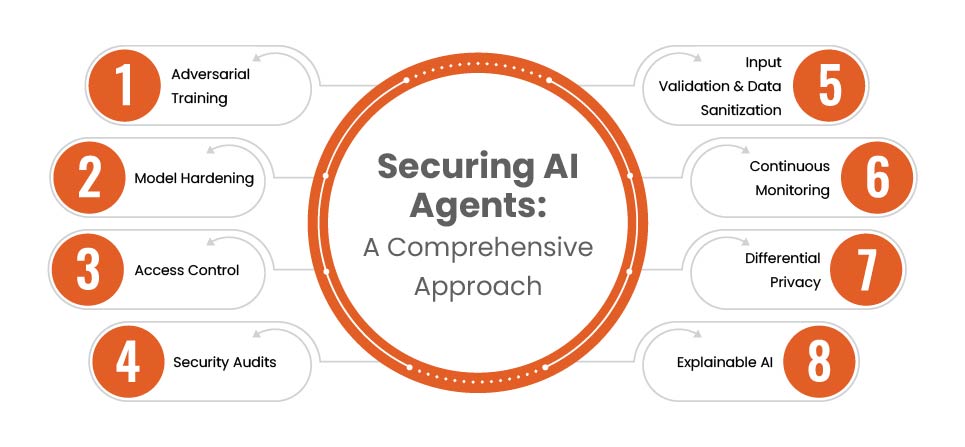
Implementation of Adversarial Training
Adversarial training is a security technique that strengthens AI models by exposing them to adversarial examples—inputs crafted to deceive the model—during the training process. It trains models with both clean and adversarial data, fine-tunes algorithms to spot malicious patterns, and teaches them to filter out attacks, boosting overall resilience. For example, self-driving cars use adversarial training to correctly interpret traffic signs even when attackers attempt to manipulate them, reducing the risk of accidents.
Input Validation and Sanitization
Validating and sanitizing all input data before it reaches an AI agent is essential to prevent poisoning attacks and inaccurate predictions. This involves using pre-processing filters to detect anomalies, applying real-time validation to block harmful inputs, and cross-checking new data against trusted datasets to avoid manipulation. For example, AI chatbots filter spam or malicious messages before replying, while healthcare AI systems verify medical data against standardized datasets to prevent fraudulent diagnosis reports.
Apply Model Hardening Techniques
Model hardening is the practice of securing AI models against tampering, reverse engineering, and malicious manipulation. This is achieved through techniques like encryption to prevent unauthorized modifications, obfuscation to make models difficult to analyze or exploit, and the use of secure enclaves such as Intel SGX or AMD SEV to store models in protected environments. For instance, AI-driven fraud detection systems in banking use encryption to safeguard risk thresholds, while cloud-based AI services rely on secure enclaves to stop attackers from reverse-engineering their models.
Implement Ongoing Monitoring and Threat Detection
Continuous monitoring enables AI systems to detect and respond to adversarial attacks in real time by analyzing behavioral patterns and unusual activity. This involves logging all interactions, using anomaly detection algorithms to spot malicious inputs, and triggering automated alerts to notify security teams of potential threats. For example, AI-powered fraud prevention tools track sudden spikes in suspicious claims to stop exploitation of underwriting models, while cybersecurity AI continuously scans network logs to identify adversarial activity.
Restrict Access With Strong Authentication & Authorization Controls
Limiting access to AI models ensures that only authorized users and systems can interact with them securely. This is achieved by implementing Multi-Factor Authentication (MFA) for system access, applying Role-Based Access Control (RBAC) to grant appropriate permissions, and restricting API usage to trusted applications. For example, AI-powered cybersecurity platforms use biometric authentication to protect sensitive threat analysis tools, while banking fraud detection systems require two-step verification before approving flagged transactions.
Implement Differential Privacy for Data Security
Differential privacy protects sensitive personal information by preventing AI models from exposing individual data while generating predictions. This is done by adding mathematical noise to data queries, generalizing results so no single data point can be traced, and avoiding model overfitting to specific users—reducing the risk of model inversion attacks. For instance, smart assistants use privacy-preserving methods to keep user conversations confidential while improving responses, and healthcare AI systems maintain patient privacy while delivering accurate medical predictions.
Conduct Regular AI Security Audits & Penetration Testing
Performing routine security audits and penetration tests helps uncover weaknesses in AI systems before attackers can exploit them. Ethical hackers simulate adversarial attacks to evaluate defenses, while security teams review models for bias, vulnerabilities, and compliance gaps. Regular updates and patches are applied to strengthen AI algorithms. For example, autonomous systems undergo stress tests to ensure they resist manipulation, large language models are audited to prevent data leaks and biased outputs, and government agencies test AI frameworks to safeguard against foreign cyber threats.
Use Explainable AI (XAI) to Improve Transparency
Explainable AI (XAI) helps make AI decision-making more transparent by providing clear, human-readable explanations of model outputs. It logs decision-making processes for expert review and uses auditing tools to reveal which factors influenced each prediction. This transparency makes it easier to detect anomalies or biases. For example, AI-driven hiring platforms can show why a candidate was shortlisted to promote fairness, while credit scoring models provide insight into lending decisions to reduce bias and improve trust.
Get in!
Join our weekly newsletter and stay updated
Consequences of Ignoring Adversarial Attacks on Your AI Agents
Adversarial attacks on AI agents pose a significant threat to businesses, with far-reaching consequences such as data breaches, financial fraud, loss of customer trust, regulatory penalties, operational disruptions, and loss of competitive advantage. These attacks can manipulate AI models to expose sensitive data like PII, financial records, or proprietary insights, approve fraudulent transactions, or disrupt mission-critical workflows like claims processing and customer service. Such incidents can result in reputational damage, lawsuits, compliance violations under regulations like GDPR or HIPAA, and costly downtime.
Moreover, intellectual property theft through adversarial exploits can hinder innovation and allow competitors to gain unfair market advantages. To address these challenges, businesses must deploy Secure AI Agents equipped with encryption, differential privacy, adversarial defense strategies, anomaly detection, and continuous monitoring to protect sensitive data, ensure reliable decision-making, and maintain compliance. Strengthening AI security is no longer optional—it is essential for safeguarding operations, preserving customer trust, and sustaining long-term business growth in an AI-driven economy.
Conclusion
As AI becomes the backbone of financial decision-making, securing AI models against adversarial attacks is no longer a technical choice but a strategic business imperative. The risks of data breaches, fraudulent approvals, compliance violations, and reputational damage are simply too high to ignore. By implementing adversarial training, model hardening, continuous monitoring, strong access controls, and differential privacy, organizations can build resilient AI systems that withstand malicious manipulation. Regular security audits, penetration testing, and the use of Explainable AI further strengthen trust and transparency, ensuring that AI-driven decisions remain accurate, unbiased, and compliant. In a world where attackers are constantly evolving, proactive AI security is the key to safeguarding financial operations, protecting customer data, and maintaining a competitive edge in the digital economy.
FAQs
- How can AI models defend against adversarial attacks?
Adversarial attacks can be countered through both reactive and proactive defenses. Reactive defenses focus on detecting and mitigating attacks after they occur, while proactive defenses aim to design machine learning models that are inherently resilient and resistant to adversarial manipulation from the start.
- What are adversarial attacks on AI models?
Adversarial AI, often referred to as adversarial attacks, involves malicious attempts to intentionally manipulate or disrupt the functioning of AI and machine learning models.





Leave a comment
Your email address will not be published. Required fields are marked *